Ein Package Manager ist der Teil von Linux, die die Verwaltung der installierten Software übernimmt. Dieser setzt auch den Weg voraus wie Software auf einem System installiert wird.
Leider gibt es für alle Linux-Distributionen keinen definierten Package-Manager und damit keinen eindeutigen Weg wie Software auf den Distributionen installiert wird.
Aktuell gibt es 3 Haupt-Paket-Typen:
.deb (kurz für „Debian binary packet“)
Dieses Format wird bei allen Debian-basierten Distributionen wie z.b. Ubuntu oder Linux Mint verwendet.
Diese Packages werden über den „Debian Package Manager“ (kurz DPKG) installiert.
.rpm (kurz für „RPM Package Manager“)
Dieses Format wird bei allen Red Hat-basierten Distributionen wie z.b. Fedora oder SUSE verwendet.
Diese Packages werden über den „RPM Package Manager“ installiert.
.tar.xz
Dieses Format ist in Wahrheit kein eigenes „Paket-Format“ wie zum Beispiel .deb oder .rpm sondern „nur“ ein komprimiertes Archiv mit dem Kompressionsformat „XZ“.
Diese „Packages“ werden über „Pacman“ installiert.
Software-Repositories
Ein Sofware-Repository ist eine online verfügbare Liste an Software-Versionen, die für einen gewissen Zweck installiert bzw. aktualisiert werden können.
Je nach verwendeter Distribution können mehr oder weniger Repositories standardmäßig vorhanden sein.
An dem oben genannten Beispiel ist ein PHP Repository für Ubuntu 18.04 „Bionic“ zu sehen um die aktuellsten PHP Versionen und Erweiterungen zu installieren.
An der Beispiel-Distribution „Ubuntu“ wird dieses Repository wie folgt in das System integriert:
Der erste Befehl fügt das Repository in das System hinzu. Der zweite Befehl führt eine Suche nach neuen Updates durch, welche möglicherweise durch das neu hinzugefügte Repository zu neuen PHP Versionen führen kann.
SSH steht für „Secure Shell“ und bezeichnet sowohl ein Netzwerkprotokoll als auch das dahinter stehende Programm um eine sichere, verschlüsselte Verbindung zwischen 2 entfernten Computern herzustellen.
SSH ist aktuell der Standard um eine Terminal-Verbindung zu einem anderen Computer zu erhalten.
Was sind die Grundvoraussetzungen für eine SSH-Verbindung?
Die erste Voraussetzung ist ein Sever, der den „SSH-Daemon“ (kurz sshd) installiert und aktiviert hat um auf diesen eine SSH-Session per Ferne herzustellen.
Die zweite Voraussetzung ist ein Client, der je nach Betriebssystem entweder schon vorinstalliert ist oder nachinstalliert werden muss. MacOS und Linux haben es meistens vorinstalliert, Windows benötigt z.B. Putty
Die dritte Voraussetzung ist ein Netzwerk, dass die 2 Computer miteinander verbindet. Ob diese Verbindung über ein lokales Netzwerk am LAN geschieht oder über das globale Internet ist hier egal.
Wie stelle ich eine SSH-Verbindung her?
Wir gehen bei folgendem Beispiel von diesem Netzwerk aus:
Server: 192.168.0.1/24 Client: 192.168.0.2/24
Nun benötigen wir den Benutzernamen und das Passwort des Server zu dem wir eine Verbindung herstellen wollen.
Benutzername: kevin Passwort: ********
Wenn wir jetzt von einem Linux oder MacOS Client ausgehen können wir im Terminal folgenden Befehl eingeben:
ssh kevin@192.168.0.1
Das heist der Befehl baut sich wie folgt zusammen:
ssh <username>@<host>
Danach erscheint eine Aufforderung für die Passwort-Eingabe. Hier bitte nicht schrecken – die visuelle Ausgabe des Passworts wird nicht angezeigt jedoch „merkt“ sich das Programm schon was über die Tastatur eingegeben wurde.
Wenn das Passwort richtig eingegeben wurde erhält man ein „fertiges“ Terminal des Servers.
Alternative für Authentifizierung – Public-Key-Auth
Wie wir alle wissen ist eine Authentifizierung über Benutzername und Passwort nicht wirklich „sicher“ da diese Daten recht einfach gestohlen, mitgehört, abgeschaut oder (auf welche Art und Weise auch immer) veröffentlicht oder verteilt wird.
Eine gute Alternative dafür ist die „Public-Key Authentication“.
Prinzip dahinter ist folgendes:
Der Client erzeugt ein Schlüsselpaar – einen „Public“ und einen „Private“ Key. Wie zu vermuten bleibt der Private-Key am Client und MUSS geheim gehalten werden. Der Public-Key wird am Server eingetragen um gewissen Benutzern das Anmelden rein über diese Methode zu erlauben.
Erstellen des Schlüsselpaars (Linux und MacOS)
ssh-keygen -t rsa
Nach der Eingabe des Befehls wird nur nachgefragt wo das Schlüsselpaar gespeichert werden soll und ob der Private-Key ein Passwort haben. Normalerweise sollte man aber den Standard-Speicherort belassen (~/.ssh/).
In diesem Ordner befinden sich nun 2 Dateien:
id_rsa
Private-Key
id_rsa.pub
Public-Key
Wenn ein Passwort auf dem Private-Key gesetzt ist kann dieser nicht ohne dieses Passwort verwendet werden.
Welche Cryptography hinter der Verschlüsselung der Public-Private-Key-Paare verwendet wird kann beim erstellen des Schlüsselpaars definiert werden.
Bekannte Methoden hierfür sind:
RSA
ECDSA
ed25519
Je nachdem wie up2date oder veraltet der Server oder der Client ist werden nur neuere oder ältere Methoden unterstützt.
Wie füge ich einen Public-Key zu meinem Server hinzu?
Wie oben beschrieben kann der Inhalt des Public-Keys unter ~/.ssh/id_rsa.pub betrachtet werden.
Alternativ kann sonst immer der folgende Befehl ausgeführt wurden um den Inhalt der Datei in die Zwischenablage zu kopieren (nur Linux und MacOS):
pbcopy < ~/.ssh/id_rsa.pub
Nun müssen wir uns auf den Server verbinden und dort im Ordner ~/.ssh/ eine Datei erstellen mit dem Namen „authorized_keys„.
Pro Zeile wird dort dann ein Public-Key eingetragen, der auf diesen User ohne Passwort sich verbinden darf.
Beispiel
Am Client (192.168.0.2) haben wir das Schlüsselpaar in ~/.ssh/ erstellt und den Public Key kopiert.
Dann verbinden wir uns auf den Server mit ssh kevin@192.168.0.2 und dem Passwort.
Danach öffnen oder erstellen wir mit unserem Text-Editor unseres Vertrauens (z.B. Vim) die Datei ~/.ssh/authorized_keys und tragen dort unseren Public Key ein.
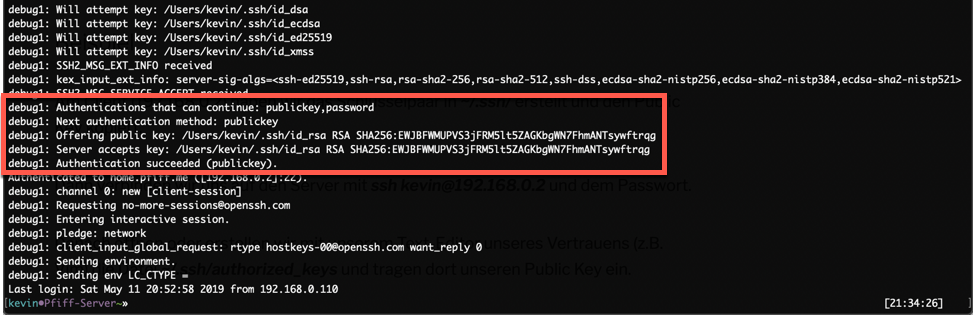
Wenn alles richtig durchgeführt wurde (und die SSH-Daemon Config des Servers nicht etwas weiteres noch voraussetzt) sollte der Login über SSH vom Client aus nun OHNE PASSWORT (wenn der Private-Key ohne Passwort erstellt wurde) funktionieren.
Weiters kann über den „Verbose-Output“ vom ssh Befehl überprüft werden ob der Public-Key erfolgreich verwendet wird.
Damit Computer untereinander in einem Netzwerk „reden“ können muss es einen Weg geben die unterschiedlichen Geräte eindeutig zu identifizieren. Für genau diesen Zweck wurde das „Internet Protocol“ (kurz IP) entwickelt.
Eine IP-Adresse ist eine im aktuell verwendeten Netzwerk eindeutige Nummer, die wie folgt aussehen kann:
IPv4: 192.168.0.10 IPv6: fe80::884:34ae:8eaf:a586
Was der genaue Unterschied zwischen IPv4 und IPv6 ist, kann im jeweilig verlinkten Beitrag extra nachgelesen werden.
Eine IP-Adresse kann so ähnlich gesehen werden wie eine Anschrift eines Hauses, nur das hier eben nicht steht „Hauptstraße 3, 8430 Leibnitz“ sondern „192.168.0.2“.
Kurz zusammengefasst musste die Anzahl an verfügbaren IP-Adressen vergrößert werden, da die 4.294.967.296 (232) verfügbaren IPv4 Adressen weltweit nicht ausreichend sind. IPv6 bietet 340.282.366.920.938.463.463.374.607.431.768.211.456 (2128) verfügbare Adressen mit dem wir definitiv länger auskommen werden.
Warum wurde das IP-Protokoll entwickelt?
Vor dem IP Protokoll war es nicht möglich mehrere unterschiedliche Netzwerke miteinander zu verbinden bzw. dass 2 Rechner aus unterschiedlichen.
Mit dem IP-Protokoll soll es so einfach wie möglich sein mehrere Computer und Netzwerke miteinander zu verbinden ohne sich um Datenflussraten (=Baudraten) oder jegliche Adressenweitergabe zu kümmern.
Hauptaufgaben vom IP-Protokoll
Adressenvergabe
Befehle für den Auf- und Abbau von Verbindungen
Datenflusssteuerung durch Start- und Stopp-Anweisungen
Fehlererkennung durch Prüfsummen, Time-Outs etc.
Automatische Fehlerkorrektur bei Fehlererkennung
Hauptmerkmale vom IP-Protokoll
Es ist architekturunabhängige
Verbindung von und zu allen Netzwerkteilnehmern möglich
dynamisches Routing
Hierfür wurden die einzelnen Bereiche und Aufgaben in einzelne „Schichten“ gegeben – das Open Systems Interconnection model, kurz OSI.
IPv4 wurde im RFC 791 im Jahre 1981 definiert. Es ist die erste Version, die weltweit zur Kommunikation von entfernten Computern verwendet wurde und ist/war ausschlaggebend für die Entwicklung des „Internets„.
Die IPv4 Adresse baut sich aus 32-Bit zusammen welche eine maximale Anzahl an 4.294.967.296 (232) verfügbaren IPv4 Adressen zur Verfügung stellt.
Netz- und Host-Anteil
Eine IP-Adresse besteht aus 2 Teilen – einem Netz-Anteil und einem Host-Anteil. Die Unterteilung wird durch die sogenannte „Netzmaske“ definiert.
Beispiel: 24-Bit-Netzwerk
Subnetzmaske
=
11111111.11111111.11111111.00000000
(255.255.255.0)
Netzteil
=
11000000.10101000.00000000
(192.168.0)
Netzwerkadresse
=
11000000.10101000.00000000.00000000
(192.168.0.0)
Erste Adresse
=
11000000.10101000.00000000.00000001
(192.168.0.1)
Letzte Adresse
=
11000000.10101000.00000000.11111110
(192.168.0.254)
Broadcast
=
11000000.10101000.00000000.11111111
(192.168.0.255)
Anzahl zu vergebenden Adressen: 28 − 2 = 254
28 deswegen, weil 32-Bit allgemein zur Verfügung stehen und 24-Bit von der Netzmaske schon „belegt“ sind. Deswegen bleiben nur mehr 8-Bit übrig.
Die Netzwerk-Adresse (192.168.0.0) und die Broadcast-Adresse (192.168.0.255) werden bei der Anzahl der zu vergebenen Adressen immer abgezogen, weil diese nicht als Client-Adressen verwendet werden sollten.
Beispiel: 16-Bit-Netzwerk
Subnetzmaske
=
11111111.11111111.00000000.00000000
(255.255.0.0)
Netzteil
=
11000000.10101000
(192.168)
Netzwerkadresse
=
11000000.10101000.00000000.00000000
(192.168.0.0)
Erste Adresse
=
11000000.10101000.00000000.00000001
(192.168.0.1)
Letzte Adresse
=
11000000.10101000.11111111.11111110
(192.168.255.254)
Broadcast
=
11000000.10101000.11111111.11111111
(192.168.255.255)
Anzahl zu vergebenden Adressen: 216 − 2 = 65,534
Vorgemerkte IP-Adressen-Bereiche
Nicht alle der 232 verfügbaren IP-Adressen haben die gleiche „Funktionalität“ sondern sind gewissen Bereichen zugewiesen. Die wichtigsten sind:
IPv6 wurde im RFC 2460 im Jahre 1998 definiert bzw. im Jahr 2017 durch den RFC 8200 ersetzt. Es ist der Nachfolger von IPv4 um diverse Probleme des nun „veralteten“ IP-Protokolls zu beheben.
Schreibweise
Da IPv6 aus 128-Bit besteht wäre eine dezimale Schreibweise gleich wie bei IPv4 nicht wirklich effizient. Daher wurde die hexadezimale Schreibweise gewählt.
2001:0db8:85a3:08d3:1319:8a2e:0370:7344
Führende Nullen in einem IPv6 Block dürfen weggelassen werden. Beispiel:
2001:0db8:0000:08d3:0000:8a2e:0070:7344
wird zu
2001:db8:0:8d3:0:8a2e:70:7344
Wenn 2 oder mehrere Blöcke hintereinander nur aus 0 bestehen können diese mit zwei : abgekürzt werden. Beispiel:
2001:db8:0000:0000:0000:0000:1428:57ab
wird zu
2001:db8::1428:57ab
Merke hier die zwei : zwischen db8 und 1428.
Jedoch darf diese Reduktion nur 1 mal ausgeführt werden! Beispiel:
2001:0db8:0:0:8d3:0:0:0
darf nur
2001:db8:0:0:8d3::
oder
2001:db8::8d3:0:0:0
werden.
Daher ist die folgende IPv6 Adresse keine ungültige Adresse:
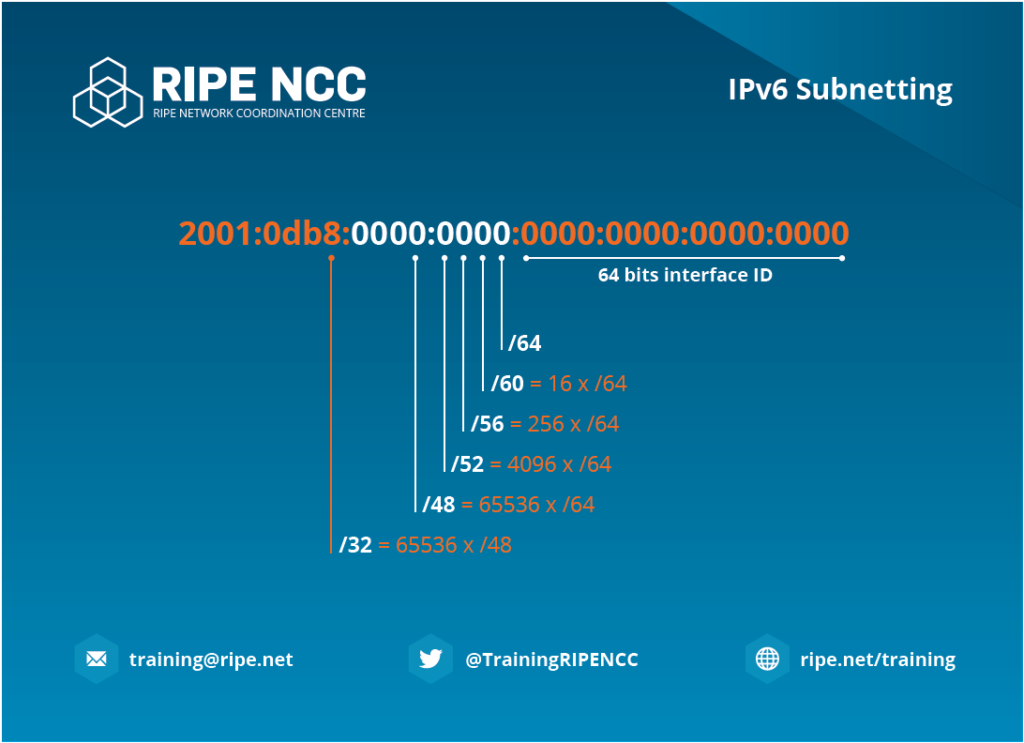
Natürlich könnte man nach /64 noch weitere Subnetze erstellen, jedoch verliert man dann ein Feature von IPv6 – die „Stateless Address Autoconfiguration“ (SLAAC) – siehe weiter unten für Beschreibung.
Link Local und Global Adresse
Bei IPv6 ist es nun standard, dass beim Verbinden eines Interfaces zu einem Netzwerk automatisch eine „link local“ und (wenn ein IPv6-Präfix vorhanden ist) eine „global“ Adresse generiert wird.
Die „Link Local“ Adresse dient – wie zu erwarten – nur für das lokal verbundene Netzwerk. Diese ist immer Teil folgendes Netzwerks: fe80::/64
Die „Global“ Adresse dient – ebenso wie zu erwarten – für das globale Netzwerk aka das „Internet“. Diese erscheint aber nur, wenn dem verbundenen Router auch ein IPv6-Präfix zugewiesen ist.
Weiters gibt es aus Security-Gründen „temporäre“ und „secured“ IPv6-Adressen. Was diese sind bzw. warum es diese gibt wird HIER genauer beschrieben.
Neue Features von IPv6
Größere Anzahl an verfügbaren Adressen
IPv6 Adressen bestehen aus 128-Bit – IPv4 besteht aus 32-Bit.
D.h. 340.282.366.920.938.463.463.374.607.431.768.211.456 (2128) im Gegensatz zu 4.294.967.296 (232) .
Zustandslose automatische Konfiguration von Clients ermöglichen (SLAAC)
Um eine IPv4-Adresse automatisch von z.B. einem WLAN-Router zu erhalten muss dieser die Funktionalität „DHCP“ aktiviert und konfiguriert haben.
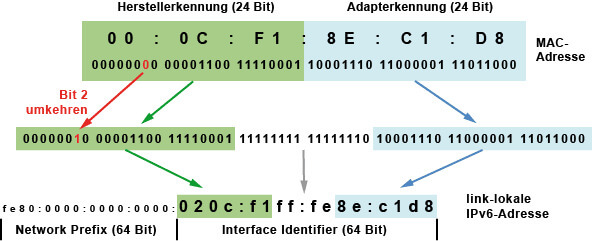
Wenn jedoch ein IPv6 Netzwerk mit einer mindest Subnetz-Größe von /64 vorhanden ist, kann die MAC-Adresse des jeweiligen Clients als Teil der IPv6-Adresse hergenommen werden. Dies gilt sowohl für den „link-local“ als auch den „global“ Bereich von IPv6-Adressen.
Hier ist nun visuell dargestellt, wie aus einer 48-Bit MAC-Adresse und dem 64-Bit „link-local“ Präfixes eine automatische IPv6-Adresse generiert wird.
Die „Internet Protocoll Security“ (IPsec) ist ein auf der 3-Schicht des OSI-Layer Models aufgebautes Protokoll, welches die Verschlüsselung und Authentifizierung von IP-Paketen ermöglicht.
Prinzipiell ist jedem HTTPS bzw. SSL und TLS bekannt, jedoch arbeiten diese Protokolle in höheren OSI-Layer-Schichten (HTTPS in der 7-Schicht und TLS in der 4-Schicht). Daher könnte trotzdem „jemand“ über die 3-Schicht gewisse Daten abfangen und/oder manipulieren.
Daher wurde zusammen mit der Entwicklung von IPv6 auch das IPsec Protokoll entwickelt.
Bewahrung des „Point-to-Point-Prinzips„
Das „Point-to-Point-Prinzip“ besagt, dass nur die Endpunkte einer Verbindung die aktiven Protokolloperationen durchführen sollen, nicht die Stationen dazwischen. Grundvoraussetzung dafür ist eine global eindeutige IP-Adresse pro Endpunkt.
Dies ist aber beim aktuell aktiven IPv4 Netzwerk nicht möglich, da nicht jedes Netzwerkgerät eine eindeutige globale IPv4 Adresse hat (siehe ebenso NAT)
Vorgemerkte IPv6 Bereiche
Wie auch bei IPv4 gibt es bei IPv6 vorgemerkte Bereiche, die einer gewissen „Funktionalität“ zugewiesen sind.
Es gibt auch diverse andere Bereiche, die für die „Konvertierung“ von IPv4 auf IPv6 Adressen verwendet werden wie z.B. 2002::/16 für das 6-to-4-Tunneling laut RFC 3056.
Was Unicast und Multicast ist wird HIER weiter behandelt.
Eine IP-Adresse kann in 2 unterschiedliche Teile aufgespalten werden – den Netz- und den Host-Bereich.
Die Unterteilung wird durch die Netzmaske definiert, welche sich gleich wie die IP-Adresse aus 32 Bit zusammenbaut (also zwischen 0.0.0.0 und 255.255.255.255)
Der Netz-Bereich geht von links nach rechts, der Host-Bereich von rechts nach links.
Beispiel
Netzmaske 255.255.255.0 – Kurzschreibweise /24 Mögliche IP-Adressen in einem Netzwerk: 254
Das heist wenn wir jetzt ein „Netzwerk“ definieren mit 192.168.0.0 haben wir die ersten 3 Zahlen 192.168.0 als Netz-Bereich und die letzte Zahl 0 als Host-Bereich.
Theoretisch hätten wir 256 IP-Adressen zur Verfügung, jedoch sind die erste und letzte IP-Adresse in einem Subnetz immer vorgegeben. Am Beispiel von /24
Daher haben wir „nur“ den Bereich von 192.168.0.1 bis 192.168.0.254 zur Verfügung was zu maximal 254 gleichzeitig vergebenen IP-Adressen führt.
Wenn wir mehr Geräte in einem Netzwerk haben wollen müssen wir die Netzmaske verkleinern. Siehe hierzu diese Tabelle:
Netzmaske
nutzbare IPv4-Adressen
Maske als Bit-Muster
255.0.0.0(/8)
max. 16.777.214
1111’1111.0000’0000.0000’0000.0000’0000
255.240.0.0 (/12)
max. 1.048.574
1111’1111.1111’0000.0000’0000.0000’0000
255.255.0.0 (/16)
max. 65.534
1111’1111.1111’1111.0000’0000.0000’0000
255.255.240.0 (/20)
max. 4094
1111’1111.1111’1111.1111’0000.0000’0000
255.255.248.0 (/21)
max. 2046
1111’1111.1111’1111.1111’1000.0000’0000
255.255.252.0 (/22)
max. 1022
1111’1111.1111’1111.1111’1100.0000’0000
255.255.254.0 (/23)
max. 510
1111’1111.1111’1111.1111’1110.0000’0000
255.255.255.0 (/24)
max. 254
1111’1111.1111’1111.1111’1111.0000’0000
255.255.255.128 (/25)
max. 126
1111’1111.1111’1111.1111’1111.1000’0000
255.255.255.192 (/26)
max. 62
1111’1111.1111’1111.1111’1111.1100’0000
255.255.255.224 (/27)
max. 30
1111’1111.1111’1111.1111’1111.1110’0000
255.255.255.240 (/28)
max. 14
1111’1111.1111’1111.1111’1111.1111’0000
255.255.255.248 (/29)
max. 6
1111’1111.1111’1111.1111’1111.1111’1000
255.255.255.252 (/30)
max. 2
1111’1111.1111’1111.1111’1111.1111’1100
255.255.255.254 (/31)
2 als P2P
1111’1111.1111’1111.1111’1111.1111’1110
255.255.255.255 (/32)
Keine
1111’1111.1111’1111.1111’1111.1111’1111
Jedoch können auch mehrere Subnetze erstellt werden um die Anzahl der IP-Adressen zu vergrößern, jedoch braucht man dann einen Router um die unterschiedlichen Subnetze miteinander verbinden zu können.
Wieso gibt es Subnetze?
Subnetze werden benötigt damit Clients wissen, ob ein IP-Packet rein im lokalen Netz weitergeleitet werden muss oder ob es an den Router (und damit an ein anderes Netzwerk) versendet werden muss.
Aber ein „Computer 3“ mit der IP 192.168.1.1/24 kann nicht mit „Computer 1“ oder „Computer 2“ kommunizieren da er in einem anderen Subnetz ist. Siehe Subnetz für weitere Details.
Im Gegensatz zum Router besitzt der Switch keine weitere Funktionalität um gewissen Netzwerkverkehr zu steuern oder zu kontrollieren.
Wenn man jetzt rein theoretisch das Netzwerk als reinen „Stromlieferanten“ sieht kann man den Switch mit einem typischen Netzverteiler vergleichen.
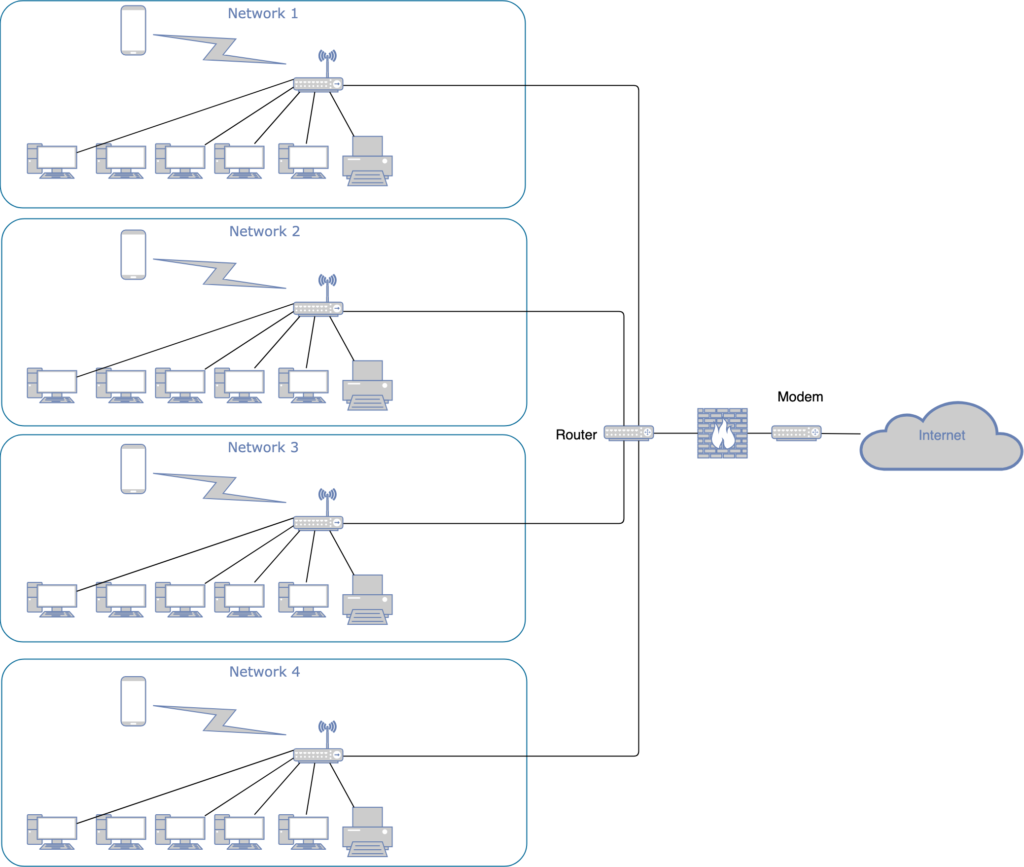
Ein Router verbindet mehrere Rechnernetzwerke miteinander, sodass Computer zwischen 2 oder mehreren Rechnernetzwerken miteinander kommunizieren können.
In dem oben beschriebenen Beispiel können je nach Konfiguration des Routers alle Geräte in den Netzwerken 1-4 miteinander kommunizieren und haben (durch die Verbindung zwischen Router und Modem) eine Verbindung ins Internet.
Router arbeiten in der 3 Schicht („Network Layer“) des OSI-Modells. In dieser Schicht stehen Informationen wie z.B. IP-Adressen des Versenders und Empfängers, Time-To-Live oder Protokoll-Typ.
Durch die IP-Adressen des Versenders und des Empfängers weiß der Router wie bzw. über welches Interface das Paket weiterverschickt werden muss.
Was sind WAN und LAN?
Da nun mehrere unterschiedliche Rechnernetzwerke aufeinander treffen braucht es nun eine Unterscheidung zwischen lokalen und anderen, weiterführenden Netzwerken.
Hierfür gibt es die Bezeichnungen „Wide Area Network“ (WAN), welches einen globalen Netzwerkbereich beschreibt, und „Local Area Network“ (LAN), welches einen privaten Netzwerkbereich beschreibt.
Meistens besitzen auch die Router einen speziell definierten „WAN“-Port, der für die einkommende Internetverbindung verwendet werden muss.
Beispiele
LAN-Netzwerke: Zuhause, Firma, Schule WAN-Netzwerke: Das ganze Internet auf der Welt
Am WAN-Port wird die einkommende Internetverbindung angeschlossen und an die LAN-Ports die diversen Clients und/oder weitere Router oder Switches für die eigene, lokale Netzwerkstruktur.
Viele Router-Geräte beinhalten ein integriertes Modem, welches die Authentifizierung bei dem „Internet-Service-Provider“ (ISP) übernimmt.
Aber manche Internet-Anbieter verwenden auch ein extra Gerät rein als Modem.