Der „System Daemon“ (kurz systemd) ist ein Programm, der unter anderem das initialisieren und verwalten von Linux-Services wie z.B. den SSH-Daemon (sshd) oder den NGINX Webserver ermöglicht.
Wieso brauche ich den systemd?
So wie auf einem Desktop-Rechner nicht immer alle Programme gleichzeitig offen sein sollen ist es auf einem Server auch gleich.
Mit dem systemd kann einerseits eingestellt werden welche Programme beim starten des Servers automatisch gestartet werden, andererseits gibt es aber auch diverse andere Befehle, die das verwalten der Services ermöglichen.
Wichtigste Befehle
systemctl
Zeige alle im systemd geladenen Services und deren Status an
systemctl start nginx
Starte den Service nginx
systemctl stop nginx
Stoppe den Service nginx
systemctl restart nginx
Startet den Service nginx komplett neu (bricht ALLE aktuellen Verbindungen ab)
systemctl reload nginx
Ladet die aktuellste Konfiguration für den Service nginx neu ein (bricht KEINE aktuellen Verbindungen ab)
systemctl status nginx
Zeige den aktuellen Status des angegeben Service an
systemctl enable nginx
Füge einen Service zum Autostart hinzu
systemctl disable nginx
Entferne einen Service vom Autostart
Ich habe keinen systemd in meiner Linux Installation!
Abhängig von der verwendeten Distribution und Version ist der systemd nicht standardmäßig installiert und konfiguriert.
Die meisten bekanntesten Distributionen haben schon vor einigen Jahren den Wechsel zu systemd durchgeführt wie z.B. Ubuntu seit 2015, Debian seit 2014, CentOS seit 2014, Arch seit 2012 und Fedora seit 2011. Siehe HIER für die aktuelle Liste.
Vorgänger zu systemd waren z.B. initd oder SysVinit (wieder abhängig von der verwendeten Distribution)
Wo befinden sich die Config-Dateien für die ganzen schon vorhandenen Services?
Die von der Distribution standardmäßig vorhandenen Services befinden sich in /lib/systemd/system.
Alle im Nachhinein installierten Services befinden sich in /etc/systemd/system.
Ebenso kann jeder vorhandene User selbst auch eigene Services in ~/.config/systemd/user erstellen.
Das ursprüngliche FTP Protokoll wurde 1985 entwickelt um Dateien über das IP-Protokoll zu versenden. Datentransfer läuft üblicherweise über Port 21.
Hauptproblem hierbei ist aber, dass die Authentifizierung NICHT VERSCHLÜSSELT läuft, d.h. wenn jemand im Netzwerk über z.B. WireShark die IP Pakete „mithört“ kann dieser ohne Probleme die Zugangsdaten auslesen.
Es wird dadurch aktuell nicht empfohlen!
FTP mit implizitem SSL
FTP mit implizitem SSL ist als nächstes entwickelt worden um das Hauptproblem von FTP zu beheben – keine Verschlüsselung. Datentransfer läuft üblicherweise über Port 990 wobei aber hier bevor ein Login oder Daten transferiert werden eine SSL oder TLS Verbindung hergestellt wird (abhängig von Server-Konfiguration). Die Basis des FTP Protokoll bleibt aber die gleiche!
Abhängig von der Server-Konfiguration (primär der gewählten Verschlüsselungsart) kann diese Methode im Live Betrieb verwendet werden, da eben eine komplett verschlüsselte Verbindung mit dieser Übertragungsmethode vorausgesetzt wird.
FTP mit explizitem TLS
FTP mit explizitem TLS ist etwas flexibler wie FTP implizitem SSL. Einerseits wird wieder die Verbindung über den Standard FTP Port 21 hergestellt wird, nur dass der Client die Möglichkeit hat nur den Login oder den gesamten Datenverkehr über eine TLS Verbindung durchzuführen.
Problem hierbei ist aber, dass von einer Zertifizierungsstelle das FTPS-Zertifikat signiert werden (was üblicherweise Kosten verursacht) muss um keine Warnung beim verbinden zum FTPS Server zu bekommen. Außer man verwendet ein selbst signiertes Zertifikat, welches aber wie gesagt am Client eine Warnung beim Verbindungsaufbau anzeigt. Aktuell habe ich keinen Weg gefunden über Let’s Encrypt ein Zertifikat für FTPS zu generieren (wie für die HTTPS Zertifikate).
Im Vergleich hierzu benötigt SFTP kein eigenes Zertifikat da hier die Verschlüsselung schon vom SSH Protokoll über die Public-Key-Auth erledigt wird.
SFTP
Das SSH File Transfer Protocol hat in der Hinsicht nichts mehr mit dem ursprünglichen FTP Protokoll zu tun da es auf dem SSH Protokoll aufbaut und alle Befehle über eine, verschlüsselte Verbindung sendet.
Daher ist diese Übertragungsmethode aktuell eine empfohlene Variante welche recht einfach eingerichtet werden kann, da das SFTP Subsystem im standardmäßig installierten SSH-Daemon bei einem Linux System nur aktiviert werden muss. Im Vergleich dazu muss für eine FTP Verbindung (egal ob verschlüsselt oder nicht) immer ein eigener FTP-Server wie z.B. VSFTP oder ProFTP installiert und konfiguriert werden.
rsync
rsync ist ein Programm, welches ebenso auf dem SSH Protokoll aufgebaut ist wie SFTP. Der Hauptunterschied ist hier aber, dass nur Daten über das Netzwerk geschickt werden, die sich auch wirklich zwischen den beiden Rechner geändert haben und nicht die gesamten Dateien.
„rsync“ ist ein Programm, welches das synchronisieren von 2 entweder lokalen oder entfernten Ordner erlaubt. Einfach gesagt, es ist eine bessere Variante vom Befehl „cp“ mit dem Dateien und Ordner kopiert werden können. Hauptmerkmal hier ist, dass es auf dem SSH-Protokoll aufbaut.
Kann ich nicht FTP oder SFTP auch nehmen?
Einfach gesagt: FTP => NEIN, SFTP => OK aber nicht so gut wie rsync
Genauere Beschreibung von Datei-Übertragungsmethoden siehe HIER.
Wieso ist rsync besser als SFTP wenn beide auf SSH basieren?
Wenn rsync auf beiden Seiten installiert ist werden NUR die Änderungen in den jeweiligen Dateien übertragen, die auch Änderungen beinhalten. Hierfür verwendet rsync einen „Delta-Kodierungs-Algorithmus“ und spart hiermit sehr viel Traffic.
Wie verwende ich rsync mit entfernten Rechner?
Voraussetzung: rsync muss auf beiden Seiten installiert sein! Kann über den Befehl „rsync --version“ herausgefunden werden. Es sollte aktuell (September 2019) mind. Version 3 installiert sein.
Gehen wir von folgenden 2 Systemen aus:
Der aktuelle Rechner (PC1), auf dem ein Ordner vorhanden ist, der auf einen extern erreichbaren Rechner (PC2) kopiert werden soll.
Befehl
rsync -aP <source> <destination>
D.h. wir sind am PC1 eingeloggt und haben im aktuellen Verzeichnis im Terminal einen Ordner wie z.B. „wordpress“ den wir auf den entfernten Rechner PC2 in den absoluten Pfad /var/www/html kopieren wollen. Für unseren entfernten Rechner nehmen wir einfach als Server-Adresse devguide.at und als Benutzer „admin“ her.
Was passiert nun? Wenn sonst nichts eingestellt ist wird entweder der Transfer nicht stattfinden oder es wird nach einem Passwort für den Benutzer „admin“ gefragt. Das hängt ganz davon ab wie der SSH-Daemon von PC2 eingestellt ist.
Damit wir aber nicht bei jedem neuen Transfer das Passwort eingeben müssen wird hier von einer schon eingerichteten „Public-Key-Auth“ ausgegangen. Siehe hierzu HIER für weitere Details.
D.h. nun haben wir eine fertig eingerichtete „Public-Key-Auth“ und wir können uns testweise ohne Passwort mit dem Befehl
ssh admin@devguide.at
auf PC2 anmelden.
Nun sollte der folgende Befehl ohne Probleme funktionieren:
Ich möchte wirklich nur die Dateien aus <source> am <destination> haben und nichts anderes!
Standardmäßig lässt rsync alle Dateien in Ruhe, die auf der <destination> Seite vorhanden sind aber nicht auf der <source> Seite vorhanden waren.
Jedoch gibt es Situationen, wo dies nicht gewünscht wird und sozusagen immer nur der <source> Stand auf die <destination> Seite geladen werden soll und sonst alles in dem angegebenen Ordner auf der <destination> Seite gelöscht werden soll.
Man hat nicht immer die Möglichkeit über ein GUIDateien zu erstellen oder zu bearbeiten sondern es steht einem nur das Terminal zur Verfügung.
Um in einem Terminal aber trotzdem Text-Dateien zu erstellen oder zu bearbeiten stehen diverse Terminal-Text-Editoren zur Verfügung. Einige bekannte sind:
Vi bzw. Vim
EMACS
Nano
In den folgenden Beispielen wird vom Editor „Vim“ ausgegangen, da ich am meisten Erfahrung damit habe und nur mit diesem arbeite.
Ist VIM schon installiert?
Am einfachsten kann man das überprüfen indem man den Befehl „vim -v“ bzw. „vi -v“ eingibt. Danach sollte eine ähnliche Anzeige wie folgt erscheinen:
Dateien erstellen und bearbeiten
Schon vorhandene Text-Dateien können mit:
vim <Dateiname>
geöffnet werden.
Danach öffnet sich die angegebene Datei im VIM Editor.
In diesem wird verständlicherweise zuerst der Inhalt der Datei angezeigt aber auch einige wichtige Informationen an der unteren Linie.
In dieser aktuellen Situation kann aber kein Text „direkt“ hinzugefügt oder bearbeitet werden sondern man muss in den „Insert“-Mode gehen.
Dieser wird mit dem Buchstaben „i“ aktiviert.
Nun kann wie gewohnt jeglicher Text hinzugefügt oder bearbeitet werden.
Datei speichern und schließen
Jetzt kommt aber die Frage auf „Wie speichere ich den aktuellen Stand?“. Es gibt ja keine Leiste oben wo man sagen kann „Datei“ => „Speichern“ oder so ähnlich.
Um in VIM Befehle auszuführen muss zuerst der „Insert“-Mode beendet werden. Dies geschieht über die Taste „ESC“. Danach verschwindet links untern das „– INSERT –“ und der „übliche“ Inhalt wird links unten angezeigt.
Hiermit sind wir wieder im „COMMAND“-Mode um Befehle auszuführen
Befehl
Beschreibung
:w
Write (Speichern)
:q
Quit (Schließen)
u
Undo (Rückgängig)
y
Yank (Kopieren)
p
Paste (Einfügen)
D.h. wenn wir eine Datei speichern und schließen wollen können wir folgenden Befehl eingeben:
:wq
Zusammengefasst sind dies nur die wichtigsten und einfachsten Informationen für den VIM-Editor. Weitere detailliertere Informationen können z.b. hier gefunden werden: https://www.howtoforge.com/vim-basics
Unterschied Vi vs Vim
„Vi“ kann prinzipiell auf allen POSIX-System installiert und betrieben werden jedoch enthält dieser nur „essentielle“ Funktionalitäten.
„Vim“ (= Vi IMproved) ist eine verbesserte Version des „standard“ Vi Editors der diverse neue Funktionalitäten zur Verfügung stellt.
Einige Beispiele dafür:
Syntax Highlighting
Undo/Redo
Split-Screen/Multifile editing
Diff Funktion um unterschiedliche Dateien zu vergleichen
Ein Package Manager ist der Teil von Linux, die die Verwaltung der installierten Software übernimmt. Dieser setzt auch den Weg voraus wie Software auf einem System installiert wird.
Leider gibt es für alle Linux-Distributionen keinen definierten Package-Manager und damit keinen eindeutigen Weg wie Software auf den Distributionen installiert wird.
Aktuell gibt es 3 Haupt-Paket-Typen:
.deb (kurz für „Debian binary packet“)
Dieses Format wird bei allen Debian-basierten Distributionen wie z.b. Ubuntu oder Linux Mint verwendet.
Diese Packages werden über den „Debian Package Manager“ (kurz DPKG) installiert.
.rpm (kurz für „RPM Package Manager“)
Dieses Format wird bei allen Red Hat-basierten Distributionen wie z.b. Fedora oder SUSE verwendet.
Diese Packages werden über den „RPM Package Manager“ installiert.
.tar.xz
Dieses Format ist in Wahrheit kein eigenes „Paket-Format“ wie zum Beispiel .deb oder .rpm sondern „nur“ ein komprimiertes Archiv mit dem Kompressionsformat „XZ“.
Diese „Packages“ werden über „Pacman“ installiert.
Software-Repositories
Ein Sofware-Repository ist eine online verfügbare Liste an Software-Versionen, die für einen gewissen Zweck installiert bzw. aktualisiert werden können.
Je nach verwendeter Distribution können mehr oder weniger Repositories standardmäßig vorhanden sein.
An dem oben genannten Beispiel ist ein PHP Repository für Ubuntu 18.04 „Bionic“ zu sehen um die aktuellsten PHP Versionen und Erweiterungen zu installieren.
An der Beispiel-Distribution „Ubuntu“ wird dieses Repository wie folgt in das System integriert:
Der erste Befehl fügt das Repository in das System hinzu. Der zweite Befehl führt eine Suche nach neuen Updates durch, welche möglicherweise durch das neu hinzugefügte Repository zu neuen PHP Versionen führen kann.
SSH steht für „Secure Shell“ und bezeichnet sowohl ein Netzwerkprotokoll als auch das dahinter stehende Programm um eine sichere, verschlüsselte Verbindung zwischen 2 entfernten Computern herzustellen.
SSH ist aktuell der Standard um eine Terminal-Verbindung zu einem anderen Computer zu erhalten.
Was sind die Grundvoraussetzungen für eine SSH-Verbindung?
Die erste Voraussetzung ist ein Sever, der den „SSH-Daemon“ (kurz sshd) installiert und aktiviert hat um auf diesen eine SSH-Session per Ferne herzustellen.
Die zweite Voraussetzung ist ein Client, der je nach Betriebssystem entweder schon vorinstalliert ist oder nachinstalliert werden muss. MacOS und Linux haben es meistens vorinstalliert, Windows benötigt z.B. Putty
Die dritte Voraussetzung ist ein Netzwerk, dass die 2 Computer miteinander verbindet. Ob diese Verbindung über ein lokales Netzwerk am LAN geschieht oder über das globale Internet ist hier egal.
Wie stelle ich eine SSH-Verbindung her?
Wir gehen bei folgendem Beispiel von diesem Netzwerk aus:
Server: 192.168.0.1/24 Client: 192.168.0.2/24
Nun benötigen wir den Benutzernamen und das Passwort des Server zu dem wir eine Verbindung herstellen wollen.
Benutzername: kevin Passwort: ********
Wenn wir jetzt von einem Linux oder MacOS Client ausgehen können wir im Terminal folgenden Befehl eingeben:
ssh kevin@192.168.0.1
Das heist der Befehl baut sich wie folgt zusammen:
ssh <username>@<host>
Danach erscheint eine Aufforderung für die Passwort-Eingabe. Hier bitte nicht schrecken – die visuelle Ausgabe des Passworts wird nicht angezeigt jedoch „merkt“ sich das Programm schon was über die Tastatur eingegeben wurde.
Wenn das Passwort richtig eingegeben wurde erhält man ein „fertiges“ Terminal des Servers.
Alternative für Authentifizierung – Public-Key-Auth
Wie wir alle wissen ist eine Authentifizierung über Benutzername und Passwort nicht wirklich „sicher“ da diese Daten recht einfach gestohlen, mitgehört, abgeschaut oder (auf welche Art und Weise auch immer) veröffentlicht oder verteilt wird.
Eine gute Alternative dafür ist die „Public-Key Authentication“.
Prinzip dahinter ist folgendes:
Der Client erzeugt ein Schlüsselpaar – einen „Public“ und einen „Private“ Key. Wie zu vermuten bleibt der Private-Key am Client und MUSS geheim gehalten werden. Der Public-Key wird am Server eingetragen um gewissen Benutzern das Anmelden rein über diese Methode zu erlauben.
Erstellen des Schlüsselpaars (Linux und MacOS)
ssh-keygen -t rsa
Nach der Eingabe des Befehls wird nur nachgefragt wo das Schlüsselpaar gespeichert werden soll und ob der Private-Key ein Passwort haben. Normalerweise sollte man aber den Standard-Speicherort belassen (~/.ssh/).
In diesem Ordner befinden sich nun 2 Dateien:
id_rsa
Private-Key
id_rsa.pub
Public-Key
Wenn ein Passwort auf dem Private-Key gesetzt ist kann dieser nicht ohne dieses Passwort verwendet werden.
Welche Cryptography hinter der Verschlüsselung der Public-Private-Key-Paare verwendet wird kann beim erstellen des Schlüsselpaars definiert werden.
Bekannte Methoden hierfür sind:
RSA
ECDSA
ed25519
Je nachdem wie up2date oder veraltet der Server oder der Client ist werden nur neuere oder ältere Methoden unterstützt.
Wie füge ich einen Public-Key zu meinem Server hinzu?
Wie oben beschrieben kann der Inhalt des Public-Keys unter ~/.ssh/id_rsa.pub betrachtet werden.
Alternativ kann sonst immer der folgende Befehl ausgeführt wurden um den Inhalt der Datei in die Zwischenablage zu kopieren (nur Linux und MacOS):
pbcopy < ~/.ssh/id_rsa.pub
Nun müssen wir uns auf den Server verbinden und dort im Ordner ~/.ssh/ eine Datei erstellen mit dem Namen „authorized_keys„.
Pro Zeile wird dort dann ein Public-Key eingetragen, der auf diesen User ohne Passwort sich verbinden darf.
Beispiel
Am Client (192.168.0.2) haben wir das Schlüsselpaar in ~/.ssh/ erstellt und den Public Key kopiert.
Dann verbinden wir uns auf den Server mit ssh kevin@192.168.0.2 und dem Passwort.
Danach öffnen oder erstellen wir mit unserem Text-Editor unseres Vertrauens (z.B. Vim) die Datei ~/.ssh/authorized_keys und tragen dort unseren Public Key ein.
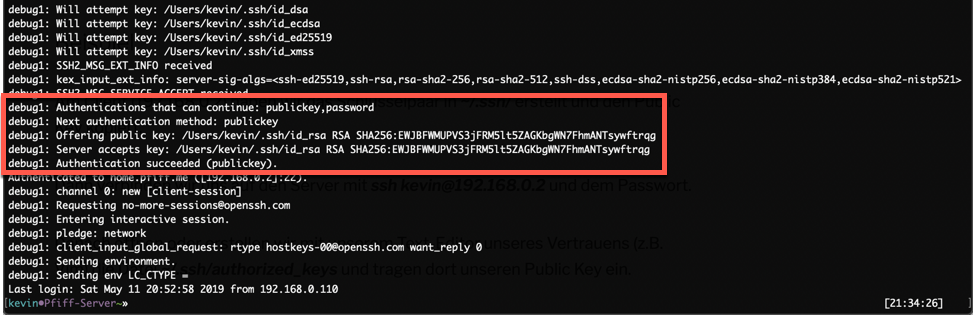
Wenn alles richtig durchgeführt wurde (und die SSH-Daemon Config des Servers nicht etwas weiteres noch voraussetzt) sollte der Login über SSH vom Client aus nun OHNE PASSWORT (wenn der Private-Key ohne Passwort erstellt wurde) funktionieren.
Weiters kann über den „Verbose-Output“ vom ssh Befehl überprüft werden ob der Public-Key erfolgreich verwendet wird.