Der PHP Composer ist ein Package-Management Tool ähnlich dem NPM oder Yarn welcher in der JavaScript-Welt bekannt ist.
Warum braucht man Dependency-Management?
Kaum jemand baut Webseiten komplett von 0 auf – d.h. Usermanagement inkl. Rollen, Medienverwaltung, Login etc.
Also wäre es ja nicht schlecht diese schon implementierten Code-Blöcke in das eigene Tool zu übernehmen, oder?
Jedoch wie bei jeder Software-Entwicklung hängt es immer sehr von der Version ab wie kompatibel 2 Code-Blöcke miteinander sind.
Genau für dieses Problem gibt es den Composer.
Composer weiß durch die Daten in der composer.json bzw. composer.lock welche Module in welcher Version installiert werden sollen und wovon diese Module wieder abhängig sind damit diese auch automatisch installiert werden.
Installation
https://getcomposer.org/download/
Mit diesen 4 Zeilen von PHP wird eine composer.phar in das aktuelle Verzeichniss gelegt.
D.h. über den folgenden Befehl können Composer-Befehle durchgeführt werden:
php composer.phar list
Damit aber Composer „global“ zur Verfügung steht muss ein User mit Admin Rechten diese Datei noch verschieben
mv composer.phar /usr/local/bin/composer
Da jeder Linux und MacOS User den Pfad /usr/local/bin/ in seiner $PATH Variable hat kann somit jeder User Composer Befehle wie folgt ausführen:
composer list
Verwendung
Hier werden ein paar essentielle Funktionalitäten vom Composer beschrieben
composer list
Zeigt alle zur Verfügung stehenden Composer Befehle an
composer create-project <boilerplate-name>
Initialisiert ein Composer-Projekt mit einem gewissen „Boilerplate“ und erzeugt eine composer.json im aktuellen Verzeichnis.
composer require <modulenmae>
Fügt das gewünschte Modul zur composer.json hinzu und führt ein composer update durch.
composer remove <modulenmae>
Entfernt das gewünschte Modul aus der composer.json und aus dem Dateisystem.
composer update
Aktualisiert die aktuell installierten Module mit den neuesten, in der composer.json definierten Updates.
Die Versionen der neu installierten Module werden in der composer.lock gespeichert.
composer install
Wenn eine composer.lock vorhanden ist werden die darin enthaltenen Module in der angegebenen Verion installiert.
Wenn keine composer.lock vorhanden ist werden die aktuellsten Versionen laut composer.json installiert und eine composer.lock generiert.
composer self-update
Aktualisiert die installierte Composer Version
composer outdated --direct
Zeigt alle Module an, die aktualisiert werden können.
Das –direct heist, dass nur Modul-Updates angezeigt werden, die in der composer.json definiert sind und nicht weitere Dependencies dahinter.
Aufbau der composer.json
Die simpelste Version einer composer.json kann über den Befehl composer init generiert werden:
{
"name": "devguide/myapp",
"authors": [
{
"name": "Kevin Pfeifer",
"email": "info@devguide.at"
}
],
"require": {}
}Prinzipiell steht hier nur wie der Name des Modul ist devguide/myapp, wer der Author des Moduls ist und ob es Dependencies zu diesem Modul gibt.
require vs. require-dev
Wie üblich in der Software-Entwicklung gibt es häufig eine Produktionsumgebung und eine Testumgebung
Damit Module in der Produktionsumgebung nicht installiert werden müssen einerseits diese in dem require-dev Bereich stehen, andererseits müssen die Module in der Produktionsumgebung auch mit der folgenden Option installiert werden:
composer install --no-dev
Somit bleiben alle Development-Module, die das Leben für uns Entwickler vereinfachen, nur auf der Testumgebung und nehmen keinen Platz auf der Live-Seite ein.
Schreibweise für die Versionen
| Name | Kurzschreibweise | Version Range |
|---|---|---|
| Exact Version | 1.0.2 | 1.0.2 |
| Version Range | >=1.0 <2.0 | >=1.0 <2.0 |
| >=1.0 <1.1 || >=1.2 | >=1.0 <1.1 || >=1.2 | |
| Hyphenated Version Range | 1.0 – 2.0 | >=1.0.0 <2.1 |
| 1.0.0 – 2.1.0 | >=1.0.0 <=2.1.0 | |
| Wildcard Version Range | 1.0.* | >=1.0 <1.1 |
| Tile Version Range | ~1.2 | >=1.2 <2.0 |
| ~1.2.3 | >=1.2.3 <1.3.0 | |
| Caret Version Range | ^1.2.3 | >=1.2.3 <2.0.0 |
Composer Patches
Wie überall bei der Softwareentwicklung funktionieren nicht immer die aktuellen Versionen zu 100% wie gewünscht.
Bevor aber eine neue Version vom Composer Modul Hersteller veröffentlicht wird gibt es meistens Patches, die angewewendet werden können.
Diese sind ganz normale .patch Files, die über GIT erstellt werden können.
Beispiel: https://www.drupal.org/files/issues/2019-02-07/3030251—entity-owner-trait—11.patch
diff --git a/consumers.install b/consumers.install
index 3ca8e25..22287bc 100644
--- a/consumers.install
+++ b/consumers.install
@@ -8,7 +8,7 @@
use Drupal\consumers\Entity\Consumer;
use Drupal\Core\Field\BaseFieldDefinition;
use Drupal\Core\StringTranslation\TranslatableMarkup;
-
+use Drupal\user\Entity\User;
/**
* Implements hook_install().
*/
@@ -161,3 +161,20 @@ function consumers_update_8105() {
'is_default' => TRUE,
])->save();
}
+
+/**
+ * 'owner_id' field should be not null.
+ */
+function consumers_update_8106() {
+ // Set owner_id to AnonymousUser id when null.
+ $anonymous_user = User::getAnonymousUser();
+
+ \Drupal::database()->update('consumer_field_data')
+ ->fields(['owner_id' => $anonymous_user->id()])
+ ->isNull('owner_id')
+ ->execute();
+
+ $entity_definition_update_manager = \Drupal::entityDefinitionUpdateManager();
+ $field_definition = $entity_definition_update_manager->getFieldStorageDefinition('owner_id', 'consumer');
+ $entity_definition_update_manager->updateFieldStorageDefinition($field_definition);
+}Voraussetzung
Um Patches mit dem Composer automatisiert anzuwenden müssen folgende Voraussetzungen erfüllt werden:
- „cweagans/composer-patches“ muss required werden
- Patching von Dependencies erlauben
{
"require": {
"cweagans/composer-patches": "^1.6.0"
},
"extra": {
"enable-patching": true
}
}Patch in composer.json hinzufügen
"patches": {
"drupal/<module_or_theme>": {
"<Description>": "<URL-to-patch>"
}
},Also z.B.
"patches": {
"drupal/recaptcha": {
"CAPTCHA validation error: unknown CAPTCHA session ID (issues/3035883)": "https://www.drupal.org/files/issues/2019-11-15/3035883-29-workaround.patch"
}
},Hier wird also das Modul drupal/recaptcha gepatched werden.
Wenn composer install oder composer update durchgeführt wird, sollte der Patch wie folgt angezeigt werden:
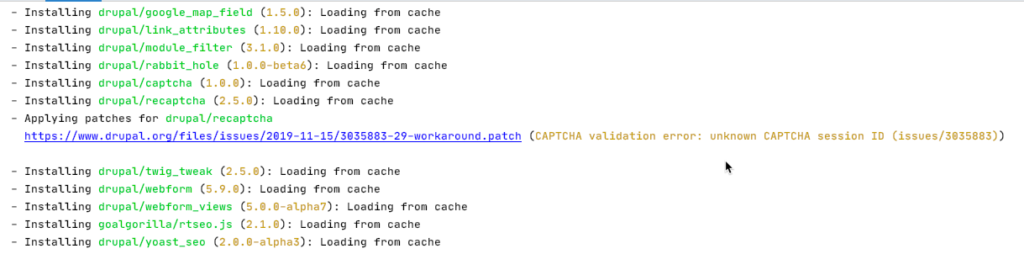
Probleme beim Patching

Wie hier zu sehen kann der Patch nicht heruntergeladen werden, da er unter der URL nicht erreichbar ist.
Hier bitte einfach die URL überprüfen ob diese auch wirklich 100% korrekt ist.
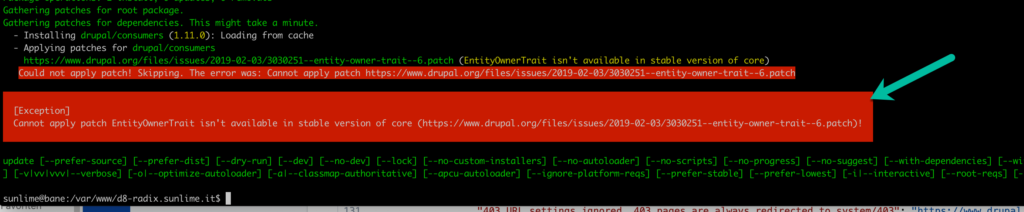
Hier ist zu sehen, dass der Patch nicht anwendbar ist.
Dies hat meistens den Grund, dass das installierte Modul den angegebenen Patch schon inkludiert hat.
Hier würde ich empfehlen den Changelog des Moduls durchzusehen ob der angegebene Patch nicht schon in einer neuen Version angewandt wurde. Dann braucht man natürlich den Patch nicht mehr händisch durchführen.
Probleme beim Update Prozess
Hier könnte es diverse Probleme geben
Berechtigungsproblem

PHP Memory Limit Problem
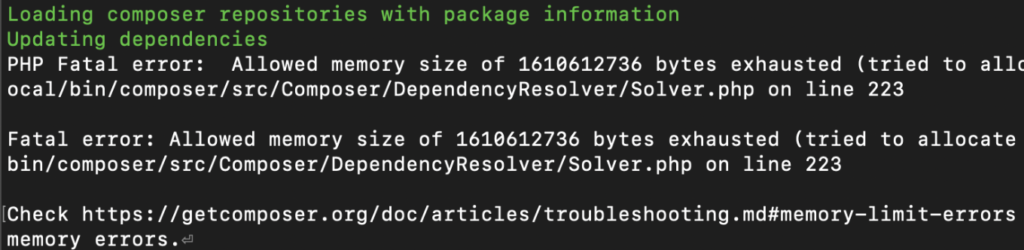
Hier kommt es natürlich immer sehr auf die Fehlermeldung an, die gerade angezeigt wird.
Das Problem mit dem Memory Limit muss über die php.ini gelöst werden. D.h. über
php -i | grep 'Loaded Configuration File'Diese gibt bei mir am MacOS folgenden Output:
Loaded Configuration File => /etc/php.iniund am Linux
Loaded Configuration File => /etc/php/7.3/cli/php.iniIn dieser Datei sollte der folgende Eintrag auf mind. 3G erhöht werden (zu mindest für Drupal Projekte)
memory_limit = 3GBerechtigunngsprobleme müssen immer je nach aktueller Umgebung gelöst werden.
Während des Update Vorgangs ist die Seite NICHT bedienbar bzw. wird Fehlermeldung anzeigen. Hier wird prinzipiell empfohlen den Wartungsmodus einzuschalten oder den gesamten Webserver kurzzeitig zu deaktivieren.
Installierte Module entsprechen nicht der composer.json bzw composer.lock
Manchmal kann es vorkommen, dass beim installieren bzw. aktualisieren von Composer Modules (bzw. Drupal Modules) nicht die richtige Version installiert wird bzw. eine defekte Version installiert.
Die einfachste Lösung hier ist es alle automatisch generierten Dateien und Ordner zu löschen und über den Composer neu zu installieren. Also:
rm -rf vendor/*
composer installBzw. für Drupal 8 Projekte
rm -rf vendor/* docroot/modules/contrib/*
composer installWo finde ich Composer Packages?
Alle aktuell vorhandenen Packages können hier durchsucht werden: https://packagist.org/